

Unlock the Power of Web Scraping as a Service
Unlock the power of web scraping as a service. Learn how it works, why you should use it, and key features to look for when selecting a provider.

How to test the quality of web data
Coverage, completeness, schema drift, freshness, and AI-readiness checks every data team should run on extracted web data.

Share of Shelf: How to Measure, Track, and Calculate It in 2026
Share of shelf measures how much of a category's visible space a brand owns at the point of purchase. This guide covers the formula, the difference between physical and digital share of shelf, the supporting metrics that give it context, and how enterprise teams track it reliably across retailers in 2026.

Digital Shelf Analytics for Clothing: How Fashion Brands Track Their Products Across Retailers
Fashion and clothing brands that sell through third-party retailers often lose visibility into how their products appear across channels. This guide covers the key digital shelf metrics clothing brands should track, the most common monitoring failures, and how to build a reliable review workflow at scale.

Web Scraping Techniques 2026: A Practical Guide to Modern Web Data Extraction
A practical guide to the most important web scraping techniques in 2026, including AI-assisted extraction, browser-based scraping, API collection, managed web scraping, product matching, and data validation for pricing intelligence and digital shelf analytics.

What Are Pricing Intelligence Tools and How Do They Work in 2026
This article explains what pricing intelligence tools are and how they work. It explores how web scraping, pricing intelligence software, and AI pricing tools help businesses monitor competitor pricing, analyse trends, and optimise pricing strategies in e-commerce.

Best Price Intelligence Tools in 2026
Explore the best price intelligence tools in 2026 and see how pricing intelligence software, AI pricing tools, and competitor price monitoring tools help ecommerce teams track market changes, optimize pricing strategies, and improve digital shelf analytics performance.

Web Scraping for Digital Shelf Analytics: What Brands Need in 2026
This article explains how web scraping supports digital shelf analytics in 2026. Learn how brands use pricing intelligence software, AI pricing tools, and competitor price monitoring tools to monitor pricing, availability, and product visibility.

From Data Noise to Action: How AI Is Changing Pricing and Digital Shelf Intelligence
E-commerce teams manage large volumes of pricing and competitor data. This article explains how AI pricing tools, pricing intelligence software, and digital shelf analytics help analyze this data and improve pricing decisions using platforms like Import.io Aperture.

The Hidden Cost of Web Scraping: Why Data Teams Are Moving to Market Intelligence Platforms
Web scraping has long been used to collect competitor data, but maintaining scraping systems can become costly and unreliable at scale. This article explores the hidden costs of scraping and why businesses are adopting automated market intelligence platforms like Import.io Aperture to monitor competitor prices, product assortment, and stock availability more efficiently.

How to Perform a Competitor Analysis using Web Scraping in 2026
Competitor analysis has evolved significantly in recent years. Learn how businesses in 2026 use web data to monitor pricing, products, SEO strategies, and customer feedback, and how modern tools like Import.io Aperture make competitor intelligence faster and easier than traditional web scraping.
.avif)
How to Create a Competitive Price Monitoring Strategy
Competitive pricing in 2026 requires real-time visibility into competitor prices, promotions, and stock levels. Learn how to build a modern price monitoring strategy and how tools like Import.io Aperture help turn web data into actionable pricing intelligence.
.jpg)
How to crawl a website the right way
Web crawling and web scraping are often confused, but they serve different purposes. This 2026 guide explains how crawlers discover URLs, how extractors pull structured data, and how modern web data strategies prioritise precision, efficiency, and compliance.
.jpg)
9 Ways to Make Big Data Visual (Updated for 2026)
Data visualization has evolved from static reports to real-time dashboards powered by AI and external web data. This 2026 update explores how visualization has changed, why clarity matters more than ever, and how modern businesses turn complex data into actionable insight.

Business Intelligence vs. Data Analytics in 2026: What’s the Difference?
Business intelligence and data analytics are often used interchangeably, but they serve different roles. This 2026 guide explains how BI focuses on present performance, analytics looks toward the future, and why both depend on high-quality data to drive smarter business decisions.

How to Get Live Web Data into Google Sheets in 2026 (Without Leaving Your Spreadsheet)
Spreadsheets are still one of the easiest ways to work with data. This guide shows how to pull live web data into Google Sheets in 2026 using Import.io, so your spreadsheet stays up to date without writing code or leaving Google Sheets.
%20(1).jpg)
Difference Between Structured and Unstructured Data
Data fuels modern businesses, but not all data is the same. This 2026 guide breaks down the differences between structured and unstructured data, explains why unstructured web data now dominates, and shows how companies use Import.io to turn it into structured, analysis-ready insights.

5 Yahoo! Pipes alternatives that are actually better than Pipes (2026 update)
Yahoo! Pipes once made it easy to combine and remix web data without code. Although it shut down years ago, the need it solved hasn’t gone away. This updated 2026 guide covers the most common Yahoo! Pipes alternatives teams use today, and explains why Import.io is the best modern upgrade for turning websites into structured, usable data.
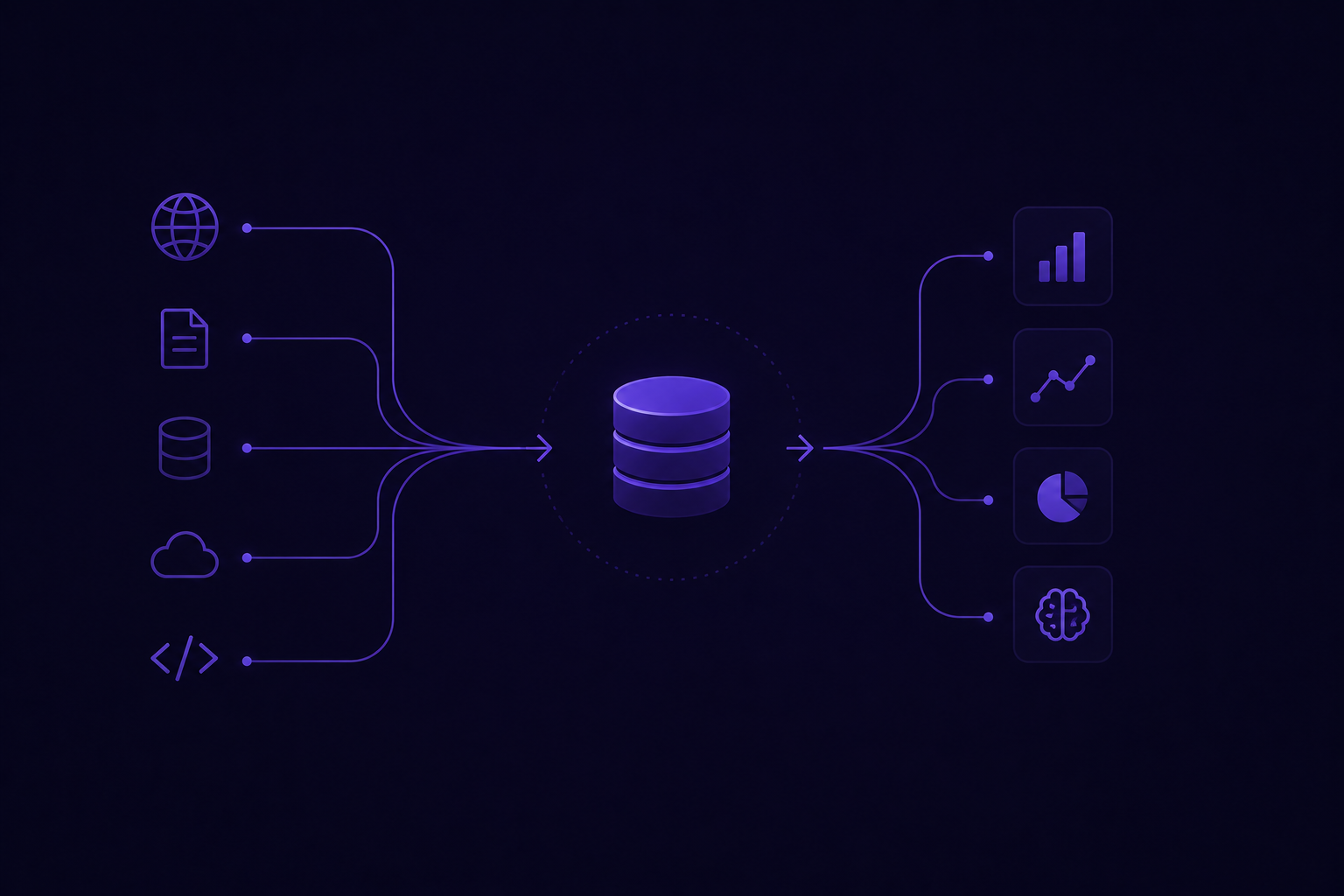
Big Data Tools for External Web Data: What Enterprise Teams Use in 2026
A practical look at the modern stack for collecting, storing, and delivering external web data, including where managed services fit and where they don't.

What Is the Digital Shelf? Definition, Components, and How Brands Win in 2026
In 2026, the digital shelf is the front line of ecommerce performance. This guide explains how brands win across Discover, Consider, and Decide by optimizing search visibility, content accuracy, reviews, pricing, and availability across retailers and marketplaces.

How to Extract Data from Websites Without APIs
In 2026, many high-value websites still don’t offer APIs, but modern teams can’t afford data blind spots. This guide explores how to extract structured data from any website using no-code tools and managed services. Whether you’re tracking competitor pricing, scraping reviews, or monitoring product changes, learn how to build scalable, compliant data pipelines without writing a single line of code.

What Is an Image URL and Why It Matters for Web Data Extraction?
Image URLs play a critical role in modern data projects. Learn what an image URL is, why it matters for web data extraction, and how teams use visual data for AI, eCommerce, and analytics.

Public Web Data: Structured, Governed, Enterprise-Ready
Public web data is powerful, but only when it’s structured and governed. Learn how enterprises transform raw online data into clean, compliant, and business-ready insights, and where Import.io fits in that journey.
.jpg)
The art of hiring data scientists
The hiring of data scientists has undergone significant changes since 2015. While demand is still high, the skill gaps have shifted: AI engineering, LLM workflows, synthetic data, and governance roles are now the most competitive. This updated 2025 guide revisits Sara Vera’s original hiring insights and expands them with modern strategies for sourcing, evaluating, and developing world-class data science talent in the age of generative AI.

Tips for organizing your Import.io data and creating reports in Google Sheets
A practical guide on structuring, cleaning, and automating web-extracted data for Google Sheets using Import.io and Sheetgo - now updated with 2025 best practices, including AI-assisted data cleaning, governance, data lineage, continuous data pipelines, and modern spreadsheet functions.

7 Tools Every Entrepreneur Should Know About
A data company's perspective on the founder toolkit. Covers the operational basics briefly, then goes deeper on the shifts that matter: how AI is reshaping workflows, why founders are building custom applications with vibe coding platforms, and how structured external web data separates guesswork from real market intelligence.

Artificial Intelligence Regulation: Let’s not regulate mathematics!
AI regulation has accelerated worldwide in 2025, led by the EU’s AI Act and increasing global efforts to ensure safety, fairness and accountability. This article explains why regulating the mathematical inner workings of AI is impractical and why a functional, risk-based, outcome-focused approach is the only path that protects innovation while managing real-world risks.

5 Industries Where Machine Learning Depends on External Web Data
Machine learning is reshaping how decisions are made in education, healthcare, logistics, finance, and retail. This guide covers practical use cases in each industry and explains why external web data quality is critical for reliable ML performance.

Understanding the Importance of Data: Why Data is Crucial for Business and Society
What exactly is data, and why is it so important? In this article, we’ll dive deeper into the world of data, exploring its different types, uses, and benefits.
Unlock the Power of Web Scraping as a Service
Unlock the power of web scraping as a service. Learn how it works, why you should use it, and key features to look for when selecting a provider.

History of Deep Learning
Explore the evolution of deep learning - from early neural networks in the 1960s to today’s foundation models and generative AI. This updated timeline (2016-2025) covers landmark breakthroughs like AlphaGo, Transformers, BERT, GPT, AlphaFold, and ChatGPT, revealing how deep learning grew from academic theory to a world-shaping technology driving science, creativity, and everyday life.

Data Mining vs Data Harvesting: What’s the Difference and Why It Matters in 2025
As organizations handle more data than ever, it’s easy to confuse data mining with data harvesting. This updated 2025 guide explains the difference: harvesting is about collecting web data, while mining is about analyzing it to uncover insights. Learn how both processes now use AI, real-time analytics, and ethical data practices to turn raw web information into business value — and how Import.io helps companies bridge the two.

The Most Hassle-Free Amazon Product Scraper
Discover how to use an Amazon product scraper to monitor prices, availability, and new products with Import.io — the ultimate web scraping platform!

Python Web Scraping: What Are The Pros and Cons
Discover the advantages and disadvantages of using Python web scraping to unlock valuable insights from the internet.

8 Fantastic examples of data storytelling
Discover 8 fantastic examples of data storytelling, from historical maps to interactive visualizations. Learn how data insights can be communicated effectively and how tools like Import.io help organizations turn complex data into actionable stories.

Data analysis: What, how, and why to do data analysis for your organization
Being a data-driven business means making decisions based on data, which provides confidence and supports successful actions. Web Data Integration automates the steps of web data analysis, making it quicker, more accurate, and more reliable for businesses to obtain real-time insights for efficient decision-making.
What is data visualization and why is it important?
Data has never been more abundant, but volume alone does not create understanding. Organisations make better decisions when information is clear, contextual and easy to interpret. Data visualization is the discipline that makes this possible.

Web Data Integration: Revolutionizing the Way You Work with Web Data
The web has become the largest, fastest-changing data source on the planet — a living ecosystem of signals, prices, reviews, trends, and insights.From finance and retail to travel and research, organizations rely on web data to understand markets, optimize operations, and outpace competitors.
.avif)
FAQ about import.io on Hacker News
Import.io was featured on Hacker News, sparking great questions about how our data-extraction platform works, from legality and IP blocking to real-world use cases, pricing, and support. This article addresses the most common questions and explains how import.io enables users to extract structured web data responsibly and effectively.
22 data experts share their predictions for 2016
Back in 2016, leading data experts predicted a future shaped by machine learning, deep learning, smart data, open data, privacy, and the rise of the data-savvy professional.
7 days of r/dataisbeautiful: a visualization that shows that data is beautiful
A quick experiment using Import.io to extract text from r/dataisbeautiful and generate a word cloud in under 30 seconds. We look at trending topics like Citi Bike, explore how word frequency patterns shape conversations, and compare the clarity of word clouds vs bar charts in data visualization.
Build a word cloud in 30 seconds
A walkthrough of how to build custom word clouds using Tagul now WordArt.com, paired with Import.io’s extraction tool. Learn how to pull clean text from any webpage, upload it into a word-cloud generator, and create unique visuals using logos and custom shapes. Includes examples using Import.io, Tableau, BigML, and more.
How we doubled our platform usage in just one month
Usage drives product success, and Import.io learned that achieving a fully structured web required radically simplifying how users extract data. This article explains how the team rethought API creation, built Data Magic, and doubled usage in a single month by turning data extraction into a one-step experience.
Eighteen Graphs About the Death Penalty
This article explores how the death penalty is applied in the United States using 18 detailed graphs drawn from data accessed via import.io and the Death Penalty Information Center. It’s divided into three parts: opposition to the death penalty (9 graphs), the deterrence argument (5 graphs), and broader trends & public opinion (4 graphs). Through visualisations covering geography, race, cost, innocence exonerations, homicide rates and public sentiment, the piece provides a data-driven look at a complex issue.

Project Policy Wins the SVC2UK Startup Weekend Competition
Project Policy won the SVC2UK Startup Weekend finals with a data-driven policy tool built using import.io. Formed at Startup Weekend Cambridge, the team impressed judges at Google Campus London and now advances to the Global Startup Battle. Runner-up Hands Free Cook Book also used import.io, highlighting the strong innovation and talent across the event.

Unlock the Secrets of Data Sourcing: What Is Data Sourcing
Data sourcing is a critical process for data scientists and analysts, as it enables them to access the most relevant datasets for their projects. Learn how to source data efficiently and safely, potential challenges, and best practices for successful results.

How Financial Analysts can leverage web data extraction
Web data extraction has become a core part of how modern financial analysts work. Here is how pricing intelligence, AI, and managed data delivery are reshaping research workflows in 2026, and where Import.io Aperture fits in.

Web Scraping Explained: How It Works and Why Businesses Rely on It
A practical guide to web scraping: how automated data extraction works, where businesses apply it in pricing, research, and competitive intelligence, and why many teams are shifting toward managed web data platforms.

Unlock the Secrets of Data Extraction of News Articles
Data extraction of news articles is an increasingly important task for data scientists and analysts. With the rapid growth in online content, it's becoming more critical to extract structured information from unstructured sources like news articles.

Everything You Need to Know About Web Scraping Legal
Web scraping can be a useful technique for obtaining and analyzing data. Yet, you must take care to abide by the website's rules and regulations in order to guarantee its legality when web scraping.

What is data aggregation? Examples of data aggregation by industry.
In today’s data-driven world, the importance of data aggregation cannot be overstated. By gathering data from multiple sources and presenting it in a summarized format, organizations can gain insights more efficiently and make more informed decisions.
What is data, and why is it important?
Whichever industry you work in, or whatever your interests, you will almost certainly have come across a story about how “data” is changing the face of our world. The collection and analysis of data play a crucial role in making informed decisions and driving insights, with data scientists being highly sought after for their expertise in processing and interpreting data.

What is data normalization and why is it important?
In the ongoing effort to use big data, you may have come across the term “data normalization.” Understanding this term and knowing why it is so important to today's business operations can give a company a real advantage as they go further in-depth with big data in the future.

How to capture an image URL
Images play a crucial role in enhancing web pages by improving readability and aesthetics, as well as conveying important information. An image URL, which is the internet address of an image on a web page, can be obtained in several ways.
How to get data from a website?
A practical guide to getting data from a website. Walks through the main extraction approaches, when to use each, and a step-by-step tutorial for pulling product, price, and listing data without writing code.

Key Insights to Optimize eCommerce Pricing
Monitoring channel pricing to ensure consistency is crucial since consumers are able to identify and take advantage of pricing irregularities more quickly and easily than before. A consistent price perception is critical. Inconsistent pricing can damage a brand’s reputation, reduce shopper loyalty and ultimately sales.

Why owning a brand’s presence online means understanding brand comparisons
This article explains why brands must understand how they’re compared to competitors across online retail sites. From search results and brand pages to product suggestions and ads, these comparisons shape consumer perception and purchase decisions. The article highlights key comparison areas and emphasizes the need for continuous monitoring to protect and strengthen a brand’s online presence.

The overlooked product page insights
Product pages are ranked as one of the most important influencers in purchase decisions and customer conversion rates, so it’s essential brands optimize their product information.

How Analytics Vendors and Agencies Use Digital Shelf Data
Platforms, consultancies, and agencies use digital shelf data to power dashboards, advisory work, and white-label products. See how the data flows.

Import.io twice as successful than web scraping at extracting complete e-commerce product data
The main web data quality problem that they were facing was that their web scraping software was collecting incomplete web data from each product page more than half of the time. Different product-data field values would be missing from nearly 60% of all product records.

2023 Guide: Scrape Data From Any eCommerce Website
The increasing volume of online data is hastening business adoption of data-driven decision-making strategies, and it has been estimated that data-driven companies are 19 times more likely to be profitable and 52% better at understanding their customers.

Customer Review Scraping: Use Cases, Methods, and Challenges
Customer reviews contain some of the most actionable data available to e-commerce teams. This guide covers the business reasons behind review scraping, where brands collect review data, and the operational challenges of doing it reliably at scale.

Silicon Review awards Import.io top workplace of the year
Silicon Review has included Import.io amongst its list of top 50 workplaces in 2020. You can see the full list here and read the interview with Gary Read our CEO below.
