
The Hidden Cost of Web Scraping: Why Data Teams Are Moving to Market Intelligence Platforms

For years, companies have relied on web scraping to collect competitor data. It started as a practical solution: build a scraper, extract the information you need, and analyze it internally.
At small scale, this approach works. A few scripts can monitor prices or product pages and feed the data into spreadsheets or dashboards.
But as organizations grow and their need for reliable market data increases, many discover that scraping introduces a range of hidden costs, from constant maintenance to unreliable datasets.
In 2026, more companies are moving toward structured market intelligence platforms like Import.io Aperture to access competitive data without the operational burden of maintaining scrapers.
This article explores the real cost of web scraping and why modern data teams are moving beyond DIY approaches.
Why Companies Start with Web Scraping?
Web scraping became popular because it offers a straightforward way to extract data from websites.
Companies often build scrapers to monitor:
- competitor prices
- product availability
- promotions and discounts
- product assortment
- customer reviews
Initially, the process seems efficient. Developers write scripts, schedule jobs, and store the extracted data in databases or spreadsheets for analysis.
However, once the number of monitored websites increases, maintaining scraping systems becomes significantly more complex.
What begins as a quick technical project can quickly evolve into a system that requires constant engineering attention.
The Real Cost of Maintaining Web Scrapers
One of the biggest misconceptions about scraping is that the primary cost is building the scraper itself.
In reality, the majority of costs appear after deployment, during ongoing maintenance.
Websites Change Constantly
Websites regularly update their layouts, HTML structures, and APIs. Even small design changes can break scraping logic.
When this happens, engineering teams must:
- identify the issue
- update selectors or extraction logic
- redeploy the scraper
- verify the data pipeline
For organizations monitoring multiple competitors, these updates can happen frequently.
Instead of running automatically, scrapers often require continuous monitoring and fixes.
Anti-Bot and Anti-Scraping Protections
Many websites actively attempt to prevent automated data extraction.
Common protection methods include:
- CAPTCHAs
- IP blocking
- rate limiting
- dynamic rendering
- bot detection systems
Overcoming these barriers often requires additional infrastructure such as rotating proxies or headless browsers.
This increases operational complexity and can introduce new points of failure.
Infrastructure and Scaling Challenges
Running scraping operations at scale requires more than just code.
Companies often need to manage:
- servers or cloud infrastructure
- proxy networks
- scraping frameworks
- scheduling systems
- monitoring and logging tools
- data pipelines
As the number of monitored pages grows, so does the infrastructure needed to support the system.
What began as a lightweight solution can quickly become a costly operational environment.
Data Quality and Reliability Issues
Even when scrapers run successfully, the data they produce may not always be reliable.
Common data problems include:
- incomplete page loads
- missing product fields
- incorrect parsing
- duplicated records
- inconsistent formatting
Data teams must then spend additional time cleaning and validating datasets before analysis can begin.
This slows down decision-making and reduces confidence in the data.
Engineering Time That Could Be Used Elsewhere
One of the most significant hidden costs is engineering time.
Developers who maintain scraping systems often spend hours diagnosing failures, adjusting extraction rules, and maintaining infrastructure.
This means technical teams are dedicating valuable resources to maintaining data collection systems instead of focusing on product development, analytics, or innovation.
Why Scraping Doesn’t Scale for Market Intelligence
Scraping can work well for limited use cases, but it becomes difficult to manage when organizations require broader competitive intelligence.
Companies may need to monitor:
- hundreds of competitors
- thousands of products
- frequent price changes
- product assortment updates
- stock availability across retailers
Maintaining scrapers across this scale introduces operational risk. If scraping systems fail, companies may miss critical market changes such as competitor promotions or pricing adjustments.
Reliable and continuously updated market data becomes difficult to guarantee with DIY scraping systems.
The Shift Toward Market Intelligence Platforms
As competitive data becomes increasingly important to business strategy, many organizations are moving away from maintaining scraping systems internally.
Instead, they rely on specialized platforms designed to deliver structured market intelligence.
Platforms like Import.io Aperture provide companies with reliable competitive data without requiring them to build or maintain scraping infrastructure.
Rather than managing scripts and proxies, teams receive structured datasets that monitor competitors across multiple dimensions.
From Scraping to Strategic Intelligence
Modern market intelligence platforms go beyond simple data extraction. They are designed to provide insights that help teams make faster and more informed decisions.
For example, Aperture enables companies to monitor:
- competitor price changes
- product assortment across retailers
- stock availability and out-of-stock events
- promotional activity
- market trends across multiple competitors
Because the data is structured and continuously updated, analytics teams can focus on strategy rather than data preparation.
This allows organizations to respond more quickly to market changes and maintain a competitive advantage.
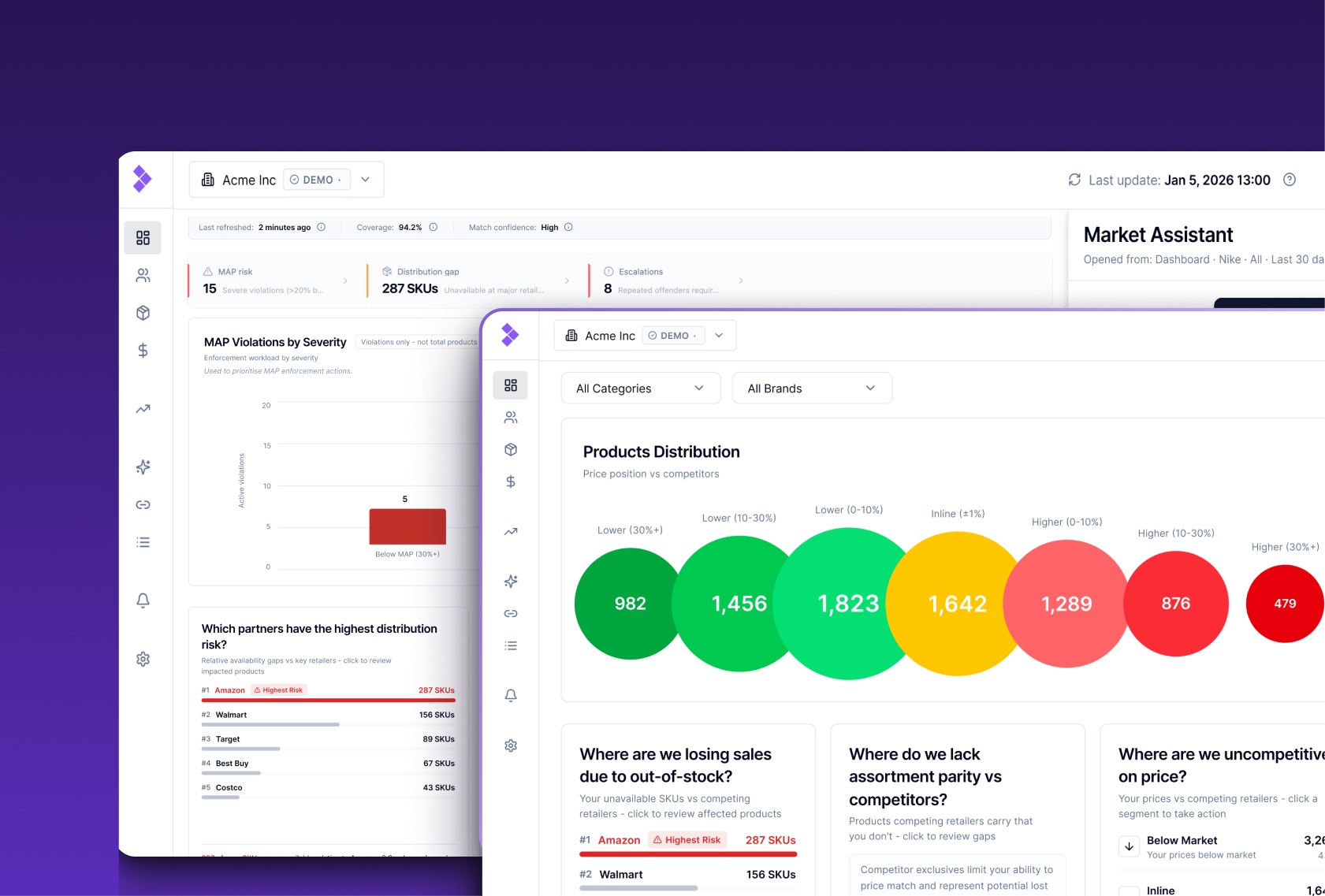
See Competitive Intelligence in Action
Maintaining web scrapers shouldn’t be the bottleneck for your competitive strategy.
With Import.io Aperture, you can access structured, continuously updated market data without building or maintaining scraping infrastructure.
Track competitor prices, monitor assortment changes, detect stock updates, and receive clean datasets ready for analysis, all in one platform.
Try the Aperture demo and explore how automated competitive intelligence works in practice here.
A New Approach to Competitive Monitoring
The shift away from web scraping reflects a broader change in how companies approach competitive data.
Instead of treating data collection as an engineering task, organizations increasingly view it as a strategic capability.
Access to reliable market data enables teams to:
- react quickly to competitor price changes
- detect promotions earlier
- monitor new product launches
- track assortment gaps across markets
Platforms like Import.io Aperture help businesses achieve this by providing scalable, reliable competitive intelligence without the operational overhead of managing scraping systems.
Conclusion
Web scraping helped many companies begin collecting competitive data, but maintaining scrapers at scale comes with significant hidden costs.
Frequent website changes, anti-bot protections, infrastructure requirements, and ongoing maintenance can turn scraping into a complex operational challenge.
As competitive intelligence becomes more central to business strategy, many organizations are adopting dedicated platforms that provide structured and reliable market data.
By moving beyond scraping and toward automated market intelligence, companies can spend less time maintaining data pipelines and more time using insights to stay ahead of the competition.
Compare managed extraction with in-house scraping.
