
Web Scraping Techniques 2026: A Practical Guide to Modern Web Data Extraction

As websites become more dynamic, personalized, and difficult to monitor at scale, web scraping techniques in 2026 need to go far beyond simple HTML extraction.
Businesses now rely on web data for pricing intelligence, competitor monitoring, digital shelf analytics, product assortment tracking, review analysis, market research, and AI workflows. This means web scraping has become more operational, more quality-driven, and more closely connected to business decision-making.
For ecommerce and pricing teams, the goal is not simply to collect web data. The goal is to collect accurate, structured, and continuously updated data to support confident decision-making.
In this guide, we explain the most important web scraping techniques for 2026, where each technique works best, and how businesses can choose the right approach depending on scale, complexity, and data quality requirements.
Quick Answer: What Are the Best Web Scraping Techniques in 2026?
The most important web scraping techniques in 2026 include:
- HTML parsing
- Browser-based scraping
- API-based data collection
- AI-assisted web scraping
- XPath and CSS selector extraction
- No-code and low-code scraping
- Managed web scraping services
- Scheduled and real-time scraping
- Product matching and entity resolution
- Data validation and quality assurance
For simple websites, HTML parsing may be enough. For ecommerce, pricing intelligence, and digital shelf analytics, businesses usually need more advanced techniques that support dynamic content, large-scale extraction, product matching, quality checks, and ongoing maintenance.
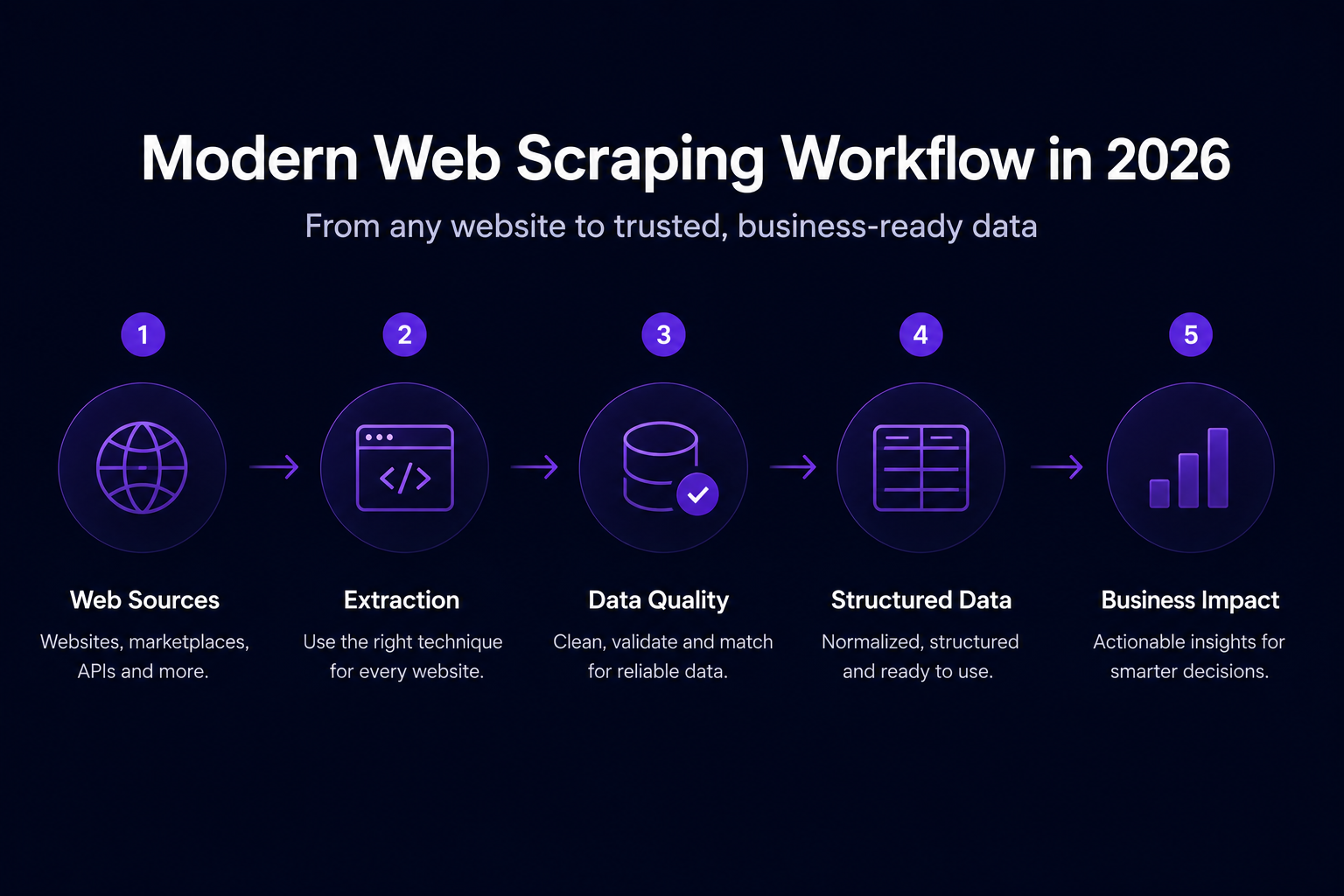
What Is Web Scraping?
Web scraping is the process of collecting data from websites and transforming it into a structured format, such as a spreadsheet, database, API feed, or analytics dashboard.
A typical web scraping workflow includes:
- Identifying target websites and pages
- Collecting page content
- Extracting relevant data fields
- Cleaning and structuring the data
- Validating accuracy
- Delivering the data to business systems
For ecommerce teams, web scraping is often used to collect product names, prices, availability, promotions, reviews, product descriptions, seller information, images, and product specifications.
For pricing teams, web scraping supports competitor price monitoring, marketplace tracking, promotion analysis, MAP compliance, and broader pricing intelligence software workflows.
Why Web Scraping Techniques Matter in 2026
Modern websites are increasingly complex. Many ecommerce and marketplace pages rely on JavaScript, dynamic content loading, personalization, regional pricing, product variants, and frequent layout changes.
This creates several challenges for businesses that depend on web data:
- Prices may change multiple times per day
- Product availability can vary by location
- Promotions may appear only under certain conditions
- Marketplaces may show different sellers for the same product
- Product pages may load key data after the page initially appears
- Website layout changes can break extraction workflows
- Raw scraped data may require cleaning before it can be used
In 2026, effective web scraping requires the right combination of extraction methods, infrastructure, monitoring, validation, and governance.
For many teams, this means moving from one-off scraping scripts to reliable web data pipelines.
Before choosing a technique, it's helpful to remember that most modern web data workflows use multiple methods. A pricing intelligence workflow, for example, may combine browser-based scraping, product matching, scheduled collection, and validation. The sections below explain where each technique fits and why teams often combine them.
1. HTML Parsing
HTML parsing is one of the most established web scraping techniques. It involves collecting a webpage's HTML and extracting specific elements, such as titles, prices, links, tables, product descriptions, or review counts.
This technique works best when the data is already available in the page HTML and the website structure is relatively stable.
Best for:
- Static websites
- Blog pages
- Public directories
- Simple product pages
- Tables and structured content
- Pages with predictable layouts
Example use case:
A market research team may use HTML parsing to collect public company names, article titles, page metadata, or directory listings from static pages.
Limitation:
HTML parsing becomes less reliable when websites rely heavily on JavaScript, personalization, infinite scroll, or frequent layout changes. A scraper may work correctly one day and fail after a minor website update.
For small projects, HTML parsing can be efficient. For business-critical data workflows, monitoring and maintenance are usually required.
2. Browser-Based Scraping
Browser-based scraping uses a real or headless browser to load the page before extracting data. This is useful when important content appears only after JavaScript runs.
Many ecommerce websites use JavaScript to load prices, product availability, customer reviews, shipping options, product variants, and recommendations. In these cases, collecting only the raw HTML may not capture the full page content.
Best for:
- JavaScript-heavy websites
- Ecommerce product pages
- Infinite scroll pages
- Pages with filters or dropdowns
- Dynamic marketplace listings
- Pages where prices load after interaction
Example use case:
Major retailers like Amazon, Walmart, and Target now use multi-layered anti-bot systems that combine TLS fingerprinting, behavioral biometrics, and JavaScript challenge evaluation before serving pricing data. A pricing team tracking daily competitor prices across these retailers needs browser-based scraping that can render full page content, handle session-based pricing, and navigate regional availability differences. In many cases, the final price only appears after a product variant, delivery postcode, or seller option is selected, which means a static HTML request will miss it entirely.
Limitation:
For teams that need browser-based scraping across many retailers but lack the infrastructure to manage headless browsers, proxy rotation, and anti-bot adaptation at scale, a managed web scraping service absorbs that operational load. The provider handles the rendering infrastructure and adapts when retailer defences change, which means the team receives structured data without running or maintaining the extraction pipeline internally.
3. API-Based Data Collection
Some websites expose data through APIs. When APIs are available and permitted, they can provide a clean and structured way to access data.
API-based collection can be useful for pulling product data, pricing information, availability, reviews, or catalogue details directly from a structured endpoint.
Best for:
- Websites with public APIs
- Partner data access
- Structured datasets
- High-frequency updates
- Reliable recurring data collection
Example use case:
A retailer may use API-based collection to receive supplier product information, inventory updates, or structured marketplace data.
Limitation:
Not all websites provide APIs. Some APIs have rate limits, restricted fields, authentication requirements, commercial access terms, or incomplete datasets.
For many competitive intelligence use cases, APIs only provide part of the data a business needs. This is why companies often combine API collection with web scraping.
4. AI-Assisted Web Scraping
AI-assisted web scraping is becoming one of the most important techniques in 2026. It helps reduce the manual work required to configure, maintain, and repair extraction workflows.
Instead of relying only on fixed selectors, AI-assisted extraction can help identify fields, understand page patterns, adapt to structural changes, and support product matching.
For example, an AI-assisted system may recognise that “sale price,” “current offer,” “discounted price,” and “member price” are all pricing-related fields across different websites.
Best for:
- Complex ecommerce websites
- Large product catalogues
- Frequently changing layouts
- Product matching across retailers
- Marketplace monitoring
- Digital shelf analytics
- Competitive pricing intelligence
Example use case:
A consumer goods brand monitoring 5,000 SKUs across 40 online retailers will encounter dozens of different page templates, naming conventions, and data structures. One retailer might label a field "Our Price," another "Sale Price," and a third "Member Price." AI-assisted extraction can recognise these as equivalent pricing fields without requiring a manually configured rule for each variation. When a retailer redesigns its product page layout, an AI-assisted system can adapt without the full rebuild that selector-based scraping typically requires. This reduces the downtime that silent failures cause, where scrapers continue running but return incomplete or incorrect data.
Limitation:
AI does not remove the need for data validation. For business-critical workflows, extracted data still needs accuracy checks, monitoring, and quality assurance.
Import.io uses AI-native extraction and self-healing data pipelines to help businesses maintain reliable web data workflows as websites change. This is especially useful for teams collecting data at scale across ecommerce sites, retailers, marketplaces, and product pages.
5. XPath and CSS Selector Extraction
XPath and CSS selectors are common techniques for identifying specific page elements. They tell the scraper where to find a piece of data within the page structure.
Selectors can be used to extract:
- Product titles
- Prices
- Ratings
- Availability text
- Image URLs
- Review counts
- Product descriptions
- Product specifications
- Seller names
Best for:
- Structured page templates
- Product listing pages
- Category pages
- Tables
- Directories
- Repeatable ecommerce layouts
Example use case:
An ecommerce analyst tracking category pages on a mid-size electronics retailer can use CSS selectors to extract product titles, prices, ratings, and stock status in a consistent table format. This works reliably as long as the retailer's page template stays stable. In practice, many retailers deploy frontend updates frequently. A recent industry analysis found that implementing version-aware selectors on one high-frequency B2B ecommerce scraping project reduced extraction downtime by 73% over two months, even as the target site pushed 14 separate hotfixes during that period. For teams without that kind of monitoring infrastructure, selector breakage is one of the most common causes of undetected data loss.
Limitation:
This maintenance burden is a common reason teams shift from self-managed selector-based scraping to managed extraction. When a provider manages the pipeline, selector breakage is detected and repaired as part of ongoing operations rather than landing on an internal engineering backlog. For a deeper comparison of the two approaches, see Import.io vs in-house scraping.
6. No-Code and Low-Code Web Scraping
No-code and low-code web scraping tools allow users to create extraction workflows without writing scripts from scratch.
These tools are useful for marketing, pricing, ecommerce, analytics, and operations teams that need access to web data but do not want to rely on engineering resources for every request.
Best for:
- Business users
- Smaller teams
- Repeatable extraction workflows
- Competitor tracking
- Market research
- Simple ecommerce monitoring
- Teams without dedicated data engineering support
Example use case:
A marketing team may want to collect competitor product messaging, pricing pages, or category descriptions without waiting for engineering support.
Limitation:
When a team outgrows what a no-code tool can handle reliably, the next step is usually either building custom scrapers internally or engaging a managed service. For most mid-size and enterprise teams, the managed route is more cost-effective because it avoids the engineering overhead of proxy management, bot-detection adaptation, and ongoing scraper maintenance. Import.io supports both paths: teams can start with self-service extraction and move to managed delivery as their data needs become more complex.
7. Managed Web Scraping Services
Managed web scraping services are designed for companies that need reliable web data but do not want to manage extraction infrastructure, maintenance, proxies, monitoring, and validation internally.
With a managed approach, the provider handles the web data pipeline from setup to delivery.
This often includes:
- Source setup
- Extractor creation
- Scheduling
- Monitoring
- Maintenance
- Data validation
- Delivery through APIs, files, or databases
Best for:
- Enterprise teams
- Large-scale web data extraction
- Complex websites
- High-volume ecommerce data
- Business-critical data feeds
- Teams with limited engineering capacity
- Use cases where accuracy and uptime matter
Example use case:
A retailer may need daily competitor price data across thousands of SKUs and multiple regions. A web scraping as a service model can reduce operational burden by handling extraction, maintenance, validation, and delivery.
Limitation:
Managed services require clear requirements. Businesses need to define target websites, fields, refresh frequency, data quality expectations, and delivery formats.
For complex use cases, this collaboration is important because web data quality depends on both technical execution and clear business rules.
8. Scheduled and Real-Time Web Scraping
Many business use cases require web data to be refreshed regularly. For pricing intelligence, competitor monitoring, and digital shelf analytics, stale data can lead to poor decisions.
Scheduled scraping allows teams to collect data at regular intervals, such as hourly, daily, weekly, or monthly.
Real-time or near real-time scraping is useful when data changes quickly, especially in ecommerce categories where prices, promotions, stock availability, and seller rankings shift throughout the day.
Best for:
- Price monitoring
- Stock tracking
- Marketplace monitoring
- Promotion tracking
- MAP compliance
- Digital shelf analytics
- Competitor assortment tracking
Example use case:
A pricing team at a consumer electronics brand monitors competitor prices across Amazon, Best Buy, and several regional retailers. Prices on Amazon can change multiple times per day depending on seller competition, stock levels, and algorithmic repricing. The team runs hourly extraction during peak trading periods and daily extraction for slower-moving categories. Each refresh cycle feeds into Aperture, where product-matched pricing data is compared against internal price positions and flagged when a competitor undercuts by a configurable threshold.
Limitation:
Higher refresh frequency increases infrastructure requirements. It also makes validation more important because errors can quickly spread to dashboards, reports, or pricing systems.
For ecommerce and pricing teams, Import.io Aperture helps turn regularly collected web data into pricing intelligence by supporting competitor price monitoring, availability tracking, product matching, and digital shelf visibility.
9. Product Matching and Entity Resolution
For ecommerce scraping, collecting prices is only part of the workflow. Businesses also need to know whether they are comparing the right products.
The same product may appear differently across retailers and marketplaces.
For example:
- Different product names
- Different image formats
- Different pack sizes
- Different bundles
- Different seller names
- Different variants
- Different regional availability
- Different product descriptions
Product matching connects equivalent products across different websites, ensuring accurate comparisons of price, availability, and assortment.
Best for:
- Ecommerce pricing intelligence
- Digital shelf analytics
- Marketplace monitoring
- Assortment benchmarking
- MAP compliance tracking
- Competitor product comparison
Example use case:
A health and beauty brand sells a 200ml moisturiser that appears on Amazon as "Brand X Hydrating Face Cream 200ml," on Boots as "Brand X Face Cream Hydrating 200ml Tube," and on a regional retailer as "BrandX Moisturiser 200ml." The packaging size is the same, but the naming, image orientation, and product description differ across all three. Without accurate product matching, a comparison report might treat these as three different products or, worse, match the 200ml product against a 50ml travel size listed at a lower price point. AI-assisted matching combined with human review on low-confidence matches helps ensure the comparison is trustworthy.
Limitation:
Product matching can be difficult when product data is incomplete or inconsistent. AI can help, but human review and validation are often needed for high-value or ambiguous matches.
This is where web scraping connects directly with pricing intelligence. Raw data needs to be structured, normalised, matched, and validated before teams can use it confidently.
10. Data Validation and Quality Assurance
Data quality is one of the most important parts of modern web scraping.
A scraper may collect data successfully, but the output may still be inaccurate if:
- The wrong field was extracted
- The price is missing
- The product variant is incorrect
- A promotion was mistaken for the base price
- The website served different regional content
- A page loaded only partially
- Sponsored listings were mixed with organic results
- The product was out of stock
- The scraper captured a placeholder value
Strong data validation techniques include:
- Field completeness checks
- Price range checks
- Historical comparison
- Duplicate detection
- Schema validation
- Product match confidence scoring
- Screenshot-based audits
- Human-in-the-loop review
- Alerts for abnormal changes
Example use case:
If a competitor's price suddenly drops by 80%, validation can help determine whether the price is real, a scraping error, a limited-time promotion, or a product mismatch.
For enterprise use cases, the goal is trusted data delivery. Extraction alone is not enough.
11. Compliance-Aware Web Scraping
Responsible web scraping should include compliance, governance, and source review.
Businesses should consider:
- Website terms
- robots.txt where relevant
- Request rates
- Data usage rights
- Personal data handling
- Internal compliance requirements
- Data storage and retention rules
Compliance-aware scraping is especially important for enterprise teams that use web data in pricing, analytics, AI workflows, or commercial decision-making.
The more important the data is to the business, the more important it is to document how it is collected, validated, stored, and used.
12. Web Scraping for AI Workflows
AI systems depend on high-quality data. Web scraping can support AI workflows by collecting current market information, product data, reviews, pricing signals, and competitive intelligence.
However, AI models and analytics tools need clean inputs. Poor extraction quality can lead to unreliable outputs.
In 2026, businesses will increasingly use web scraping to support:
- AI pricing tools
- Competitive intelligence systems
- Product recommendation models
- Market monitoring dashboards
- Digital shelf analytics platforms
- Demand and assortment analysis
- Review and sentiment analysis
- Product content optimization
For these use cases, freshness, structure, and accuracy matter as much as volume.
Prefer a tool that handles these techniques for you? 30-day free trial, 5,000 successful queries, no credit card required.
From Friction to Flow: Turning Web Scraping Into a Reliable Data Operation
Modern web scraping is no longer only about getting a scraper to run. For many teams, that part has become easier. The harder part is keeping the workflow reliable as websites change, markets move, and business teams depend on the data.
Retailers update page layouts. Marketplaces change seller displays. Prices can vary by region, session, or availability. Product information often appears in different formats across different websites.
That is why web scraping in 2026 needs to work as an operational data workflow. Teams need to monitor sources, detect issues, validate results, match products, normalize data, and deliver clean outputs into pricing, ecommerce, analytics, and AI systems.
A reliable workflow assumes that websites will change. It includes checks for missing fields, unexpected values, product mismatches, and unusual price movements before the data reaches dashboards or decision-making systems.
It also connects collection frequency to the business need. Some use cases only need weekly updates. Others, such as competitor price monitoring or marketplace tracking, may require daily, hourly, or near-real-time data.
The goal is to move from fragile extraction to reliable intelligence. Web scraping still starts with data collection, but the long-term value comes from turning that data into a trusted system teams can use with confidence.
How to Choose the Right Web Scraping Technique
The right technique depends on the website, the data, and the business goal. A simple static page may only need HTML parsing. A dynamic ecommerce site may require browser-based scraping or API-aware collection. A pricing or digital shelf workflow may also need product matching, normalisation, validation, and scheduled monitoring.
The best starting point is to look at how the data will be used after collection.
For a quick one-time dataset, a lightweight extraction method may be enough. Recurring competitor monitoring requires a more stable workflow with scheduling, source monitoring, and maintenance. Pricing intelligence depends on accurate product matching, price validation, and freshness controls. Digital shelf analytics needs broader coverage across products, sellers, availability, content, ratings, reviews, and marketplaces.
When web data supports important business decisions, quality assurance should be built in from the beginning. Teams need to know that the data is complete, accurate, and current, and delivered in a format that supports action.
In 2026, the strongest web scraping strategies connect extraction with reliable data operations. The technique still matters, but the long-term value comes from turning collected data into trusted, repeatable intelligence.
How Web Scraping Techniques Connect to Business Use Cases
Different teams need different levels of web data support.
A marketing team may only need occasional monitoring of competitor content. A pricing team may need daily or hourly competitor price data. An ecommerce team may need digital shelf visibility across multiple retailers. A data science team may need structured web data to support AI models.
This is why web scraping in 2026 is less about choosing one technique and more about choosing the right workflow.
For example:
- SaaS extraction works well when teams want direct control over repeatable extraction workflows.
- Managed web scraping services work well when teams need reliable data delivery without managing infrastructure.
- Pricing intelligence platforms work well when teams need to turn web data into decisions, alerts, dashboards, and competitive insights.
Import.io supports these different needs through SaaS web data extraction, managed web scraping services, and Aperture for pricing intelligence and digital shelf monitoring.
This gives businesses flexibility depending on whether they need extraction tools, managed data delivery, or a full pricing intelligence workflow.
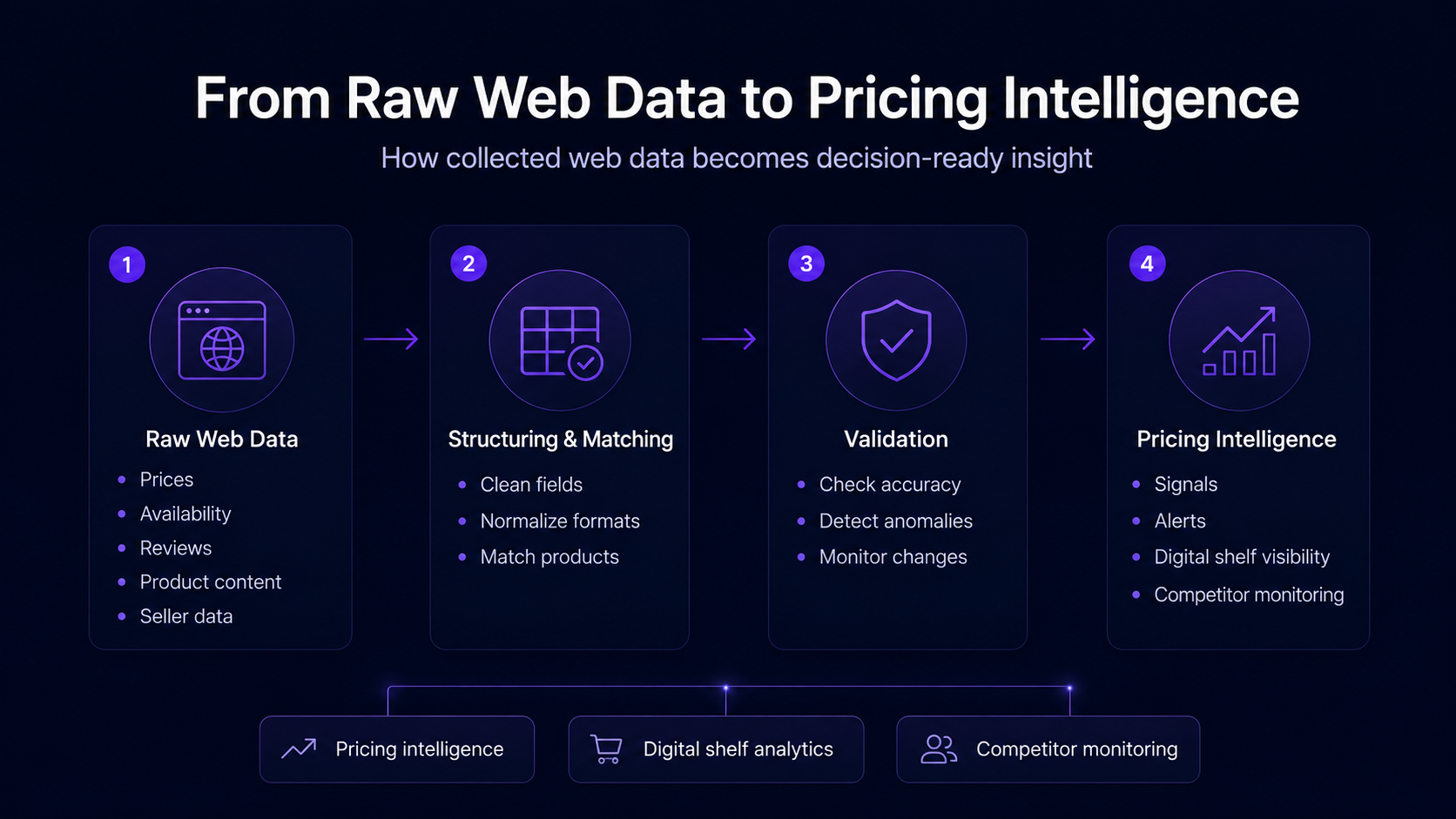
Example: A pricing team may start with a simple scraper to track competitor prices once a week. As the category becomes more competitive, that workflow usually needs more structure. The team may need daily or hourly updates, product matching across retailers, alerts when prices move, and validation to avoid acting on bad data. At that point, web scraping becomes part of a pricing intelligence workflow.
Where Import.io Fits Into Modern Web Scraping
Import.io helps businesses collect, structure, validate, and use web data at scale.
For teams that want more direct control, Import.io’s SaaS capabilities support extractor creation, automation, scheduling, monitoring, and structured data delivery.
For organisations that need reliable web data without managing scraping operations internally, Import.io’s managed service supports end-to-end web data extraction, including setup, maintenance, validation, and delivery.
For ecommerce and pricing teams, Import.io Aperture helps turn extracted web data into pricing intelligence. Aperture supports competitor price monitoring, product matching, availability tracking, MAP compliance, and digital shelf visibility.
This makes Import.io relevant across the full web data workflow:
- Extracting data from websites
- Structuring and normalising the output
- Monitoring extraction pipelines
- Maintaining data flows as websites change
- Validating data quality
- Delivering data into business systems
- Turning web data into pricing and digital shelf intelligence
The best approach depends on the team’s goals, internal resources, and data quality requirements.
Final Thoughts on Web Scraping Techniques in 2026
Web scraping techniques in 2026 are more advanced, operational, and closely tied to business outcomes than earlier approaches.
Basic scraping techniques still have a place, especially for simple websites and smaller projects. But companies that rely on web data at scale need more resilient methods. Dynamic extraction, AI-assisted setup, browser-based scraping, product matching, compliance-aware workflows, managed services, and data validation are becoming essential.
For businesses using web data for pricing intelligence, competitor monitoring, or digital shelf analytics, the value comes from reliable, structured, and continuously updated data.
Modern platforms like Import.io help teams move from fragile extraction workflows to scalable web data operations. With SaaS extraction, managed web scraping services, and Aperture for pricing intelligence, businesses can choose the level of support that matches their data needs and internal resources.
For teams that need reliable web data for pricing intelligence, competitor monitoring, or digital shelf analytics, Import.io can support the full workflow from extraction and validation to managed delivery and decision-ready insights.
