
Data Mining vs Data Harvesting: What’s the Difference and Why It Matters in 2025
Updated October 2025
As data becomes the fuel of modern business, understanding how it’s collected and analyzed is more important than ever.
This updated 2025 guide breaks down the difference between data mining and data harvesting, how both have evolved with AI, and how your organization can use them effectively.
There are many data terms being used today: data analytics, data mining, data warehousing, big data, data harvesting, data science, and web scraping, to name a few.
For anyone outside the analytics world, it can sound like a blur of jargon.
The reality is that these terms describe different parts of one ecosystem - how data is collected, organized, and turned into insight.
Getting them right can help your team make smarter, faster business decisions.
In this article, we look at data mining and data harvesting. They’re often mentioned together but actually describe two very different steps in the data journey.
Learn how you, can be consistent and competitive with Product Details
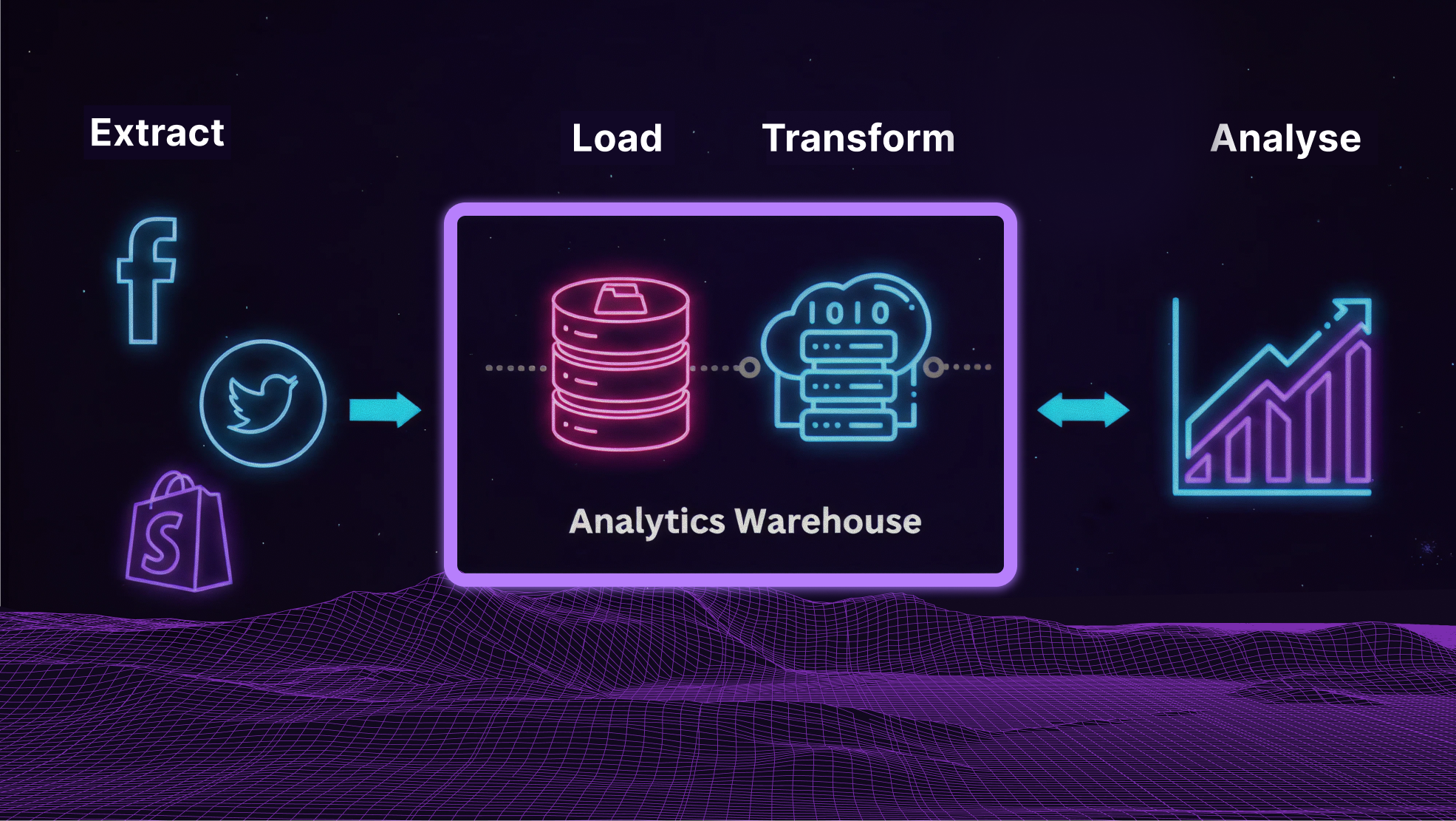
The Modern Data Mining Process
- Define clear business goals
- Collect and integrate data from multiple sources
- Clean and prepare the dataset
- Build and test predictive models
- Evaluate and refine for accuracy
- Deploy, monitor, and improve continuously
If you want to see how this process works in practice, explore our AI powered data extraction tools.
Why Data Mining Matters in 2025
Organizations use data mining to:
- Segment customers and predict churn
- Detect fraud and anomalies
- Forecast demand
- Optimize internal processes
And in 2025, new technologies are reshaping how mining works:
- Real time streaming analytics replacing static reports
- AI driven pattern recognition for more accurate forecasts
- Automated feature engineering to speed up model creation
- Multi modal data mining that combines text, audio, and visuals in one model
You can learn more about these developments in our AI and data automation insights from our team. Don't hestitate to reach out.
What Is Data Harvesting?
Data harvesting, also known as web scraping or data extraction, focuses on collecting data from online sources.
If data mining is about analyzing, data harvesting is about gathering.
The comparison fits well. It is like harvesting crops.
Instead of wheat or corn, you are collecting web data such as product listings, prices, reviews, posts, or images that can later be analyzed.
How Data Harvesting Works
Data harvesting tools and crawlers access websites, APIs, or public databases to collect both structured and unstructured information.
Common examples:
- Retailers tracking competitor pricing
- Marketing teams collecting public reviews or social posts
- Researchers pulling open government or marketplace data
“Harvesting gives you the raw material. Mining turns it into gold.”
Why Organizations Harvest Data
Companies harvest web data to:
- Understand markets and competitors
- Enrich internal datasets
- Generate qualified sales leads
- Automate monitoring or alerts
With so much information available online, harvesting is often the first step in any modern data strategy.
Learn more about managed data services for enterprises that help automate and scale compliant data collection.
Compliance and Ethics
While powerful, harvesting requires careful handling:
- Websites may limit automated scraping through their terms of service
- Personal data must only be collected or stored with consent
- Regulations such as GDPR and CCPA set clear legal boundaries
Responsible harvesting focuses on publicly available, non sensitive data, gathered transparently through APIs or licensed data sources.
How They Work Together
Most organizations use both processes as part of a continuous loop:
- Harvest data from the web or internal systems
- Prepare it through cleaning and formatting
- Mine it to find patterns and predictions
- Act on those insights to improve performance
Collect, analyze, act, repeat
For more insight check our other blogs.
New Trends in 2025
Data Mining Trends
- Generative AI for creating synthetic data
- Streaming mining for instant insights
- Explainable AI to make models transparent
- Privacy preserving learning to protect user data
Data Harvesting Trends
- API first, permission based collection
- Focus on data quality rather than quantity
- Cloud native data pipelines for scalability
- Stronger emphasis on ethical sourcing and compliance
How to Use Both Effectively
- Start with a clear business goal
- Follow data privacy laws and platform rules
- Collect only what is truly necessary
- Apply AI powered mining to generate deeper insights
- Automate monitoring and updates to keep models current
- Review and refine your data pipeline regularly
More on trust and ethics
Final Thoughts
Data harvesting and data mining form the backbone of any data driven strategy.
Used responsibly, harvesting fuels your analytics engine and mining transforms that information into meaningful decisions.
Both have evolved with AI and automation, but human judgment and ethics remain the key differentiators.
If your team wants to unlock the full potential of web data, Import.io provides the tools and expertise to harvest clean, structured data and turn it into actionable insight.
Updated October 2025
As data becomes the fuel of modern business, understanding how it’s collected and analyzed is more important than ever.
This updated 2025 guide breaks down the difference between data mining and data harvesting, how both have evolved with AI, and how your organization can use them effectively.
There are many data terms being used today: data analytics, data mining, data warehousing, big data, data harvesting, data science, and web scraping, to name a few.
For anyone outside the analytics world, it can sound like a blur of jargon.
The reality is that these terms describe different parts of one ecosystem - how data is collected, organized, and turned into insight.
Getting them right can help your team make smarter, faster business decisions.
In this article, we look at data mining and data harvesting. They’re often mentioned together but actually describe two very different steps in the data journey.
Learn how you, can be consistent and competitive with Product Details
The Modern Data Mining Process
- Define clear business goals
- Collect and integrate data from multiple sources
- Clean and prepare the dataset
- Build and test predictive models
- Evaluate and refine for accuracy
- Deploy, monitor, and improve continuously
If you want to see how this process works in practice, explore our AI powered data extraction tools.
Why Data Mining Matters in 2025
Organizations use data mining to:
- Segment customers and predict churn
- Detect fraud and anomalies
- Forecast demand
- Optimize internal processes
And in 2025, new technologies are reshaping how mining works:
- Real time streaming analytics replacing static reports
- AI driven pattern recognition for more accurate forecasts
- Automated feature engineering to speed up model creation
- Multi modal data mining that combines text, audio, and visuals in one model
You can learn more about these developments in our AI and data automation insights from our team. Don't hestitate to reach out.
What Is Data Harvesting?
Data harvesting, also known as web scraping or data extraction, focuses on collecting data from online sources.
If data mining is about analyzing, data harvesting is about gathering.
The comparison fits well. It is like harvesting crops.
Instead of wheat or corn, you are collecting web data such as product listings, prices, reviews, posts, or images that can later be analyzed.
How Data Harvesting Works
Data harvesting tools and crawlers access websites, APIs, or public databases to collect both structured and unstructured information.
Common examples:
- Retailers tracking competitor pricing
- Marketing teams collecting public reviews or social posts
- Researchers pulling open government or marketplace data
“Harvesting gives you the raw material. Mining turns it into gold.”
Why Organizations Harvest Data
Companies harvest web data to:
- Understand markets and competitors
- Enrich internal datasets
- Generate qualified sales leads
- Automate monitoring or alerts
With so much information available online, harvesting is often the first step in any modern data strategy.
Learn more about managed data services for enterprises that help automate and scale compliant data collection.
Compliance and Ethics
While powerful, harvesting requires careful handling:
- Websites may limit automated scraping through their terms of service
- Personal data must only be collected or stored with consent
- Regulations such as GDPR and CCPA set clear legal boundaries
Responsible harvesting focuses on publicly available, non sensitive data, gathered transparently through APIs or licensed data sources.
How They Work Together
Most organizations use both processes as part of a continuous loop:
- Harvest data from the web or internal systems
- Prepare it through cleaning and formatting
- Mine it to find patterns and predictions
- Act on those insights to improve performance
Collect, analyze, act, repeat
For more insight check our other blogs.
New Trends in 2025
Data Mining Trends
- Generative AI for creating synthetic data
- Streaming mining for instant insights
- Explainable AI to make models transparent
- Privacy preserving learning to protect user data
Data Harvesting Trends
- API first, permission based collection
- Focus on data quality rather than quantity
- Cloud native data pipelines for scalability
- Stronger emphasis on ethical sourcing and compliance
How to Use Both Effectively
- Start with a clear business goal
- Follow data privacy laws and platform rules
- Collect only what is truly necessary
- Apply AI powered mining to generate deeper insights
- Automate monitoring and updates to keep models current
- Review and refine your data pipeline regularly
More on trust and ethics
Final Thoughts
Data harvesting and data mining form the backbone of any data driven strategy.
Used responsibly, harvesting fuels your analytics engine and mining transforms that information into meaningful decisions.
Both have evolved with AI and automation, but human judgment and ethics remain the key differentiators.
If your team wants to unlock the full potential of web data, Import.io provides the tools and expertise to harvest clean, structured data and turn it into actionable insight.
